What is vMSC?
vSphere Metro Storage Cluster (vMSC) is a new certified configuration for high availability storage architectures. vMSC configuration is designed to maintain data availability beyond a single physical or logical site. A storage device configured in the vMSC configuration is supported after successful vMSC certification. All supported storage devices are listed in the
VMware Storage Compatibility Guide.
What is a Hitachi NAS (HNAS) Synchronous Disaster Recovery (SyncDR) Cluster?
Hitachi NAS is a scalable enterprise Network File Systems (NFS)/network-attached storage (NAS) system, widely deployed, serving NFS datastores to vSphere environments and Server Message Block (SMB) file services.
Hitachi NAS (HNAS) Synchronous Disaster Recovery (SyncDR) Cluster software allows an existing Hitachi NAS cluster to stretch over two locations. The complete solution includes a synchronous replication solution using Hitachi TrueCopy Remote Replication between two Hitachi SAN storage systems, providing storage high availability and disaster recovery in a campus or metropolitan area.
A HNAS with SyncDR Cluster software configuration consists of two Hitachi NAS nodes, each located at the same data center campus or across two different physical locations, clustered together with access to their respective Hitachi SAN storage. SyncDR Cluster software transparently manages and initiates failover with any failure in access to the storage configuration without causing disruption to data availability.
Note: In the stretched configuration, NFS datastores are highly available and can be accessed by vSphere hosts on both sites simultaneously.
If there is a site failure, the other data center Hitachi NAS node continues to provide I/O access to the data volumes.
Solution Overview
A vMSC architecture on NFS/NAS platform (Hitachi Enterprise) provides an ideal solution for higher availability and uptime by clustering physical data centers within metro distances. The metro storage cluster solution from Hitachi Data Systems (HDS) consists of storage systems, providing replicated storage as a single filesystem(s) from different geographically distributed sites. This design enables high availability of services by allowing virtual machine migration between sites with no downtime.
Note: The Hitachi NAS (HNAS) platform leverages Hitachi Enterprise Virtual Server (EVS) failover functionality to automatically protect against node failures.
Additionally, the Hitachi NAS solution layers local Synchronous Mirroring (Hitachi TrueCopy Remote Replication), SyncDR Cluster software and geographic separation to achieve higher levels of availability. TrueCopy synchronously mirrors data across the two halves of the Hitachi NAS Cluster solution by writing data to the two storage pools (or spans):
- The local storage pool (local span) actively serving data and
- The remote storage pool (remote span) normally not serving data.
A VMware HA/Distributed Resource Scheduler (DRS) cluster is created across the two sites using ESXi 5.x hosts and managed by vCenter Server 5.x. The vSphere Management, vMotion, and virtual machine networks are connected using a redundant network between the two sites. It is assumed that the vCenter Server managing the HA/DRS cluster can connect to the ESXi hosts at both sites by using a uniform host access configuration solution. In a uniform host access configuration, the primary datastore(s) on filesystem(s) are synchronously replicated to a read-only secondary filesystem(s). ESXi hosts from different sites can access the storage devices on both sites, but can see the two filesystems as a single entity.
On local storage failure, the remote storage is activated and takes over data-serving operations. With site failover, both the EVS and Storage pool are activated in the remote/secondary storage. No data loss occurs because of synchronous mirroring. The solution allows both manual and automatic activation of the secondary copy of the data.
Metro Storage Cluster solution with Hitachi NAS
It is a HNAS Storage platform with SyncDR Cluster software configuration. This illustration shows an overview of it.
Note: This illustration is a simplified representation and does not indicate the redundant front-end components, such as Ethernet and Fibre channel switches.
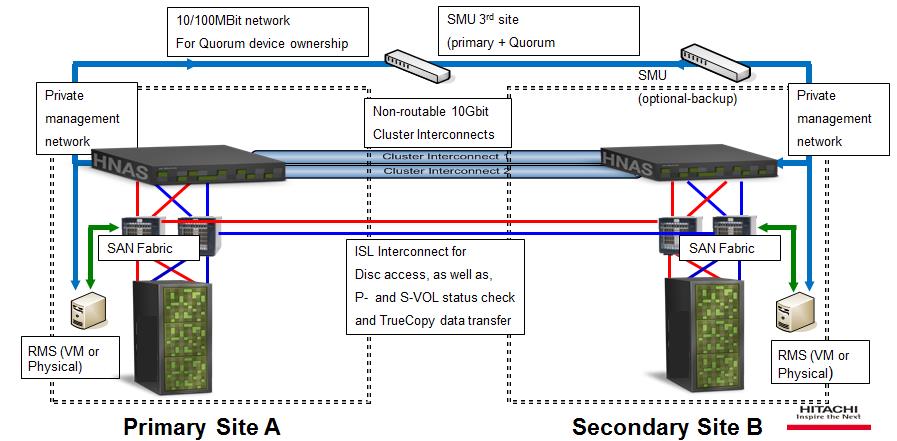
System Management Unit (SMU)
SMU is required for the management of the HNAS environment. It implements a quorum device for the cluster. SMU must be located at a third location to prevent a cluster shut down when one location dies (50%-plus-one rule).
Replication Monitoring Station (RMS)
RMS continuously monitors the HNAS nodes and Hitachi SAN storage controllers. There are two RMS systems, one per location, running on a virtual machine or a physical server. It helps in an automatic fail over by switching the mirror direction and performing storage pool fail over.
Configuration Requirements
These requirements must be satisfied to support this configuration:
- The round-trip latency between the Ethernet networks in the two sites must be less than 10 milliseconds (uniform host access). The IP network supports the VMware ESXi hosts and the VSP/HAM management interface.
- The round-trip latency for synchronous storage replication must be less than 5 milliseconds.
- The minimum throughput available between the two sites must be 622 Mbps, to support vMotion of virtual machines across ESXi hosts spread across both data centers.
- The ESXi hosts in both data centers must have a private network on the same IP subnet and broadcast domain.
- ESXi hosts in the SyncDR configuration must be configured with at least two different IP networks, one for storage and the other for management and virtual machine traffic. The Storage network handles NFS traffic between ESXi hosts and Hitachi nodes. The second network (virtual machine Network) supports virtual machine traffic as well as management functions for the ESXi hosts. End users can choose to configure additional networks for other functionality such as vMotion/Fault Tolerance.
Note: VMware recommends this as a best practice, but it is not a strict requirement for a vMSC configuration.
- The VMware NFS datastores and associated filesystems configured for the ESX servers are provisioned on Hitachi TrueCopy mirrored storage pool.
- VMware vCenter Server must be accessible from all vSphere hosts on both sites.
- The same IP network on which the virtual machines are located must be accessible to the ESXi hosts on both sites. This helps clients accessing the virtual machines (that are running on ESXi hosts on both sites) to function smoothly when there is any VMware HA-triggered virtual machine restart event.
- For NFS/iSCSI configurations, a minimum of two uplinks for the controllers must be used. An interface group (link aggregate) must be created using the two uplinks.
- The data storage locations, including the boot device used by the virtual machines, must be accessible from ESXi hosts in both data centers.
- The maximum number of vSphere hosts in the HA cluster must not exceed 32.
- Hitachi NAS Platform microcode 11.2 or later with SyncDR version 2.0.5 or later is required.
- SyncDR Cluster License
For more information on HNAS platform for VMware, see the Reference Architecture Guide.
Tested Scenarios
This table outlines the tested vMSC scenarios and its results.
| vMSC Tests | Test Description | Observed Behavior |
| SP_And_Network_Partition_Failure | - A single storage processor fails at the primary site and is followed by simultaneous total site‐to‐site network partition. The partition includes both SAN and network connections.
- The virtual machines running at Site A continues to run.
- The virtual machines running at Site B continues to run.
- No virtual machine failovers occur, assuming that the virtual machines are located at the biased site of the volume at each site.
| passed |
| SVD_Back_End_SAN_Array_Failure | - Applies to SVD only.
- A back-end array used by the SVD at one site has failed completely.
- If the ESXi datastores are on multiple arrays, all such arrays on one site must fail.
- The datastore (distributed volume) continues to operate with the surviving array on the other site.
- No HA/DRS impact.
- After the array is restored, the distributed volumes are rebuilt.
- The rebuild speed varies based on the hosts I/O and transfer size settings in the SVD.
| - HNAS back-end array is failed at both sites one by one.
- The virtual machines become inaccessible at the time of failure.
- After recovery of array, reverse snapshot is done.
- The virtual machines become accessible after revert snapshot.
|
| SP_Failure | - This test verifies that virtual machine I/O and simultaneous import and export operations to the same datastore from
multiple hosts can survive a SP failure. - No HA/DRS impact.
| passed |
| HBA_Port_Failover | - This test verifies that virtual machine I/O and simultaneous import and export operations to the same datastore from multiple hosts can survive a single HBA or port failure.
- No HA/DRS impact.
| Ethernet Switch port connected to CNA of server is disabled/enabled alternatively. No end user effect. |
| Storage_WAN_Link_Failure | - This test verifies that the I/O continues at the biased side of each distributed volume after a SVD site‐to‐site storage
network WAN link outage. - On the unbiased side the I/O fails.
- Sometimes, if a running virtual machine is on the unbiased side, it is restarted on the biased side.
| WAN link between two sites failed. No end user impact |
| ESXi_Host_Reboot | - This test verifies that HA/DRS balances load on the surviving hosts in the cluster on host failure.
- The virtual machines automatically restart on the surviving ESXi hosts.
| - HA of vCenter Server automatically restarts the virtual machines of a failed host to any of the surviving ESXi hosts.
- The downtime of the virtual machines may vary depending on the time taken by HA of vCenter Server.
|
| vCenter_Failure | - This test verifies that a vCenter Server failure does not impact HA/DRS.
- This test runs with no network latency and storage WAN latency of 3 ms.
| No end user impact |
Storage_Management_Server_Failure | - This test verifies that when the SVD management server at either site fails, it does not immediately impact the virtual machines running on a HA/DRS cluster.
- The SVD management server fails when it is shut down or powered off.
| No end user impact |
| Single_ESX_All_Network_Failure | - This test verifies that when all network connections to a single
ESXi fail, the virtual machines run without any impact. - This test runs with a network latency of 5 ms and storage
WAN latency of 0 ms.
| - All the network connections for the server are failed.
- The virtual machines become inaccessible temporarily as per the test requirement.
|
| Total_Site_A_Failure | - This test verifies HA/DRS behavior during a total Site A
failure. - Virtual machines running at Site A fail over to Site B by HA.
- Virtual machines running at site‐B continue to run without any impact.
- The failure includes the SVD and ESXi hosts at Site A, but does not include the storage site broker.
| - Complete Site A is failed with a downtime for Site A virtual machines and datastores.
- Span failover occurs with the help of hnassyncdr_monitor.py script, running in a RMS server.
|
| Total_Site_B_Failure | - This test verifies HA/DRS behavior during a total Site B failure.
- Virtual machines at Site B fail over to Site A by HA.
- Virtual machines running at Site A continue to run without any impact.
- The failure includes the SVD and ESXi hosts at Site B, but does not include the storage site broker.
| - Complete Site B is failed with a downtime for Site B virtual machines and datastores.
- Span failover occurs with the help of hnassyncdr_monitor.py script, running in a RMS server.
|
| Total_Site_A_And_Site_B_Failure | This test verifies that the HA/DRS cluster can be brought up successfully in the event of a total failure of Site A and Site B. | - Site A and Site B are failed alternatively with a downtime for the respective virtual machines and datastores.
- Span failover occurs with the help of hnassyncdr_monitor.py script, running in a RMS server
|
| HA_Network_Partition_Failure | - This test verifies that ESXi hosts network partition has no impact on the running virtual machine(s).
- The HA heartbeat continues exchange through the virtual machine datastores.
- This test runs with a network latency of 5 ms and storage
WAN latency of 3 ms.
| No end user impact |
| VMotion_And_Storage_Management_Failure | - This test verifies that a simultaneous vMotion network
partition and an SVD management network partition have no impact on the running virtual machines. - This test runs with a network latency of 10 ms and storage
WAN latency of 0 ms.
| Passed |
| vMotion_IO_Test | - This test stresses the storage and TCP/IP stack for an extended period of time.
- The tests run I/O to RDM.
- This test runs with a network latency of 10 ms and storage
WAN latency of 5 ms.
| No end user impact |
| Storage_Array_Failure | - This test covers the scenario in which the SVD at a single site has failed.
- In a non-uniform host access configuration, the ESXi at the
failed site experiences an All Paths Down (APD) scenario and virtual machines hang. - In a uniform host access configuration, the virtual machines at the site in which the SVD has failed continues to run without any impact.
| NAS node is failed for each site.
No end user impact. |
| ESX_PDL_Condition | - This test verifies that when a Permanent Device Loss occurs
in the ESX, the impacted virtual machines fail over using HA to
the surviving ESXi hosts.
Note: This test requires that the parameter TerminateVMOnDefault be set, to ensure that virtual machines are downed in a PDL condition.
| The downtime of the virtual machines may vary depending on the time taken by HA of vCenter Server. |
