Druva Phoenix for VMware Cloud on AWS
Article ID: 328090
Updated On:
Products
VMware Cloud on AWS
Issue/Introduction
Purpose
This article provides information about the support of Druva Phoenix on VMware Cloud that covers VMware Cloud on AWS and VMware Cloud on Dell EMC.
Disclaimer: The partner solution referenced in this article is a solution that is developed and supported by a partner. The use of this product is also governed by the end user license agreement of the partner. You must obtain from the partner the application, support, and licensing for using this product. For more information, see druva.com.
Resolution
Here is a summary of use cases, solution architecture, solution components, and support information.
Druva Phoenix can back up virtual machines created in VMware Cloud (VMC) Software-Defined Data Center (SDDC) similar to the on-premise vSphere-based data center and supports the following use cases:
This article provides information about the support of Druva Phoenix on VMware Cloud that covers VMware Cloud on AWS and VMware Cloud on Dell EMC.
Disclaimer: The partner solution referenced in this article is a solution that is developed and supported by a partner. The use of this product is also governed by the end user license agreement of the partner. You must obtain from the partner the application, support, and licensing for using this product. For more information, see druva.com.
Resolution
Here is a summary of use cases, solution architecture, solution components, and support information.
VMware Cloud on AWS
Use cases supported on VMware Cloud on AWSDruva Phoenix can back up virtual machines created in VMware Cloud (VMC) Software-Defined Data Center (SDDC) similar to the on-premise vSphere-based data center and supports the following use cases:
- The backed-up virtual machines can be restored to:
- Same VMC SDDC from where they were backed up.
- Different SDDC in VMC.
- An on-premise data center.
- Similarly, virtual machines backed up from an on-premise data center can be restored to a VMC SDDC.
- Uses native VMware API to back up and restore data.
- Leverages VMware CBT to track incremental changes.
- Offers file-level recovery to a virtual machine.
- Leverages hot add transport mode for backups.
- Ability to configure virtual machines based on tags, datastores, clusters, and automated policy configuration.
- Automated disaster recovery in AWS with orchestration and failback capabilities.
- SQL application-aware backups and restores.
- ROBO backup / restore and DRaaS to AWS
Resolution
Solution Architecture
Druva Phoenix is built on cloud-native architecture. Unlike traditional solutions that are hosted in AWS and leverage S3 or Glacier, Druva Phoenix is built on top of AWS services leveraging native AWS services like S3, Glacier, EC2, and DynamoDB. This helps to reduce the storage and compute needed, and with the scalability of metadata index.
The following diagram illustrates the Druva Phoenix architecture for VMC on AWS.
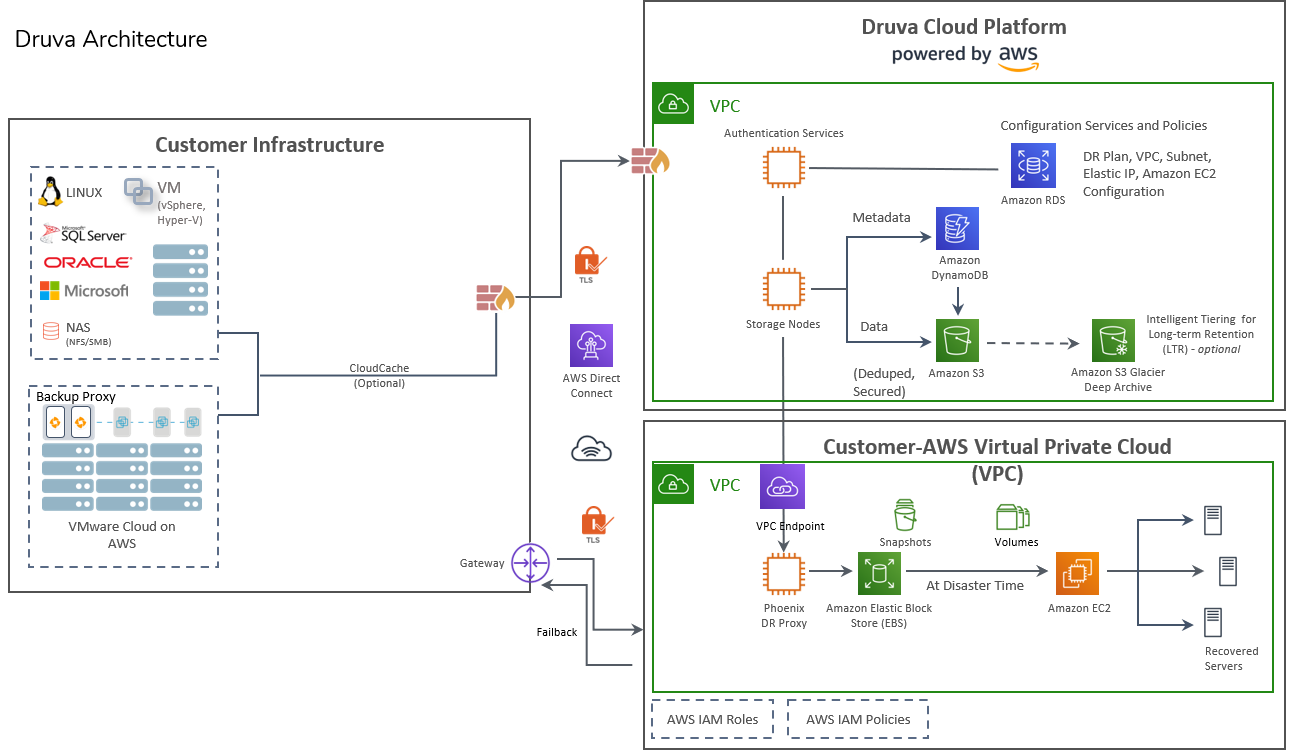
As illustrated in the diagram:
The Druva Phoenix backup proxy is required for backing up virtual machines. Backup proxy is the critical component that sits between your data center and Phoenix cloud and is responsible for performing backup and restore of virtual machines. For more information, see About Phoenix backup proxy for VMware.
Optional software component—CloudCache is used for ROBO use case to store data locally on-premise. For more information, see Phoenix CloudCache.
Ensure VMC SDDC firewall rules are configured to enable http/https traffic over port 443 for the communication through Compute and Management Gateways.
The backup proxy communicates with Druva on port 443. The communication is outbound only and you need to create an outbound traffic rule. The backup proxy also communicates with the vCenter on port 443 to understand the VMware hierarchy and communicates with the virtual machines to perform backups and restores.
Features of the Backup Solution
Support Information
Druva Phoenix is built on cloud-native architecture. Unlike traditional solutions that are hosted in AWS and leverage S3 or Glacier, Druva Phoenix is built on top of AWS services leveraging native AWS services like S3, Glacier, EC2, and DynamoDB. This helps to reduce the storage and compute needed, and with the scalability of metadata index.
The following diagram illustrates the Druva Phoenix architecture for VMC on AWS.
As illustrated in the diagram:
- To back up and restore virtual machines hosted on your VMware Cloud setup, deploy the Phoenix backup proxy. The Phoenix backup proxy is the client-side component that detects the virtual machines running on your setup and executes the backup and restore requests from the Phoenix Cloud.
- VMC does not support the NBD mode of transport for data transfer (backup over production LAN) and instead uses the hot add transport mode for backups.
- Data is processed at the backup proxy end for deduplication and the deduplicated data is then sent over to the Phoenix Cloud.
- By default, data flows over the public network (restricted to the AWS environment) to the Phoenix Cloud.
- Optional software component—CloudCache is used for ROBO use case to store data locally on-premise.
The Druva Phoenix backup proxy is required for backing up virtual machines. Backup proxy is the critical component that sits between your data center and Phoenix cloud and is responsible for performing backup and restore of virtual machines. For more information, see About Phoenix backup proxy for VMware.
Optional software component—CloudCache is used for ROBO use case to store data locally on-premise. For more information, see Phoenix CloudCache.
Steps to configure VMC with Phoenix
- Review the prerequisites to install the backup proxy.
- Deploy the backup proxy and register your VMware setup with Druva Phoenix. For more information, see Deploy the first backup proxy and register the VMware setup.
- Configure your virtual machines for backup. Configure Virtual Machines for Backup.
Ensure VMC SDDC firewall rules are configured to enable http/https traffic over port 443 for the communication through Compute and Management Gateways.
The backup proxy communicates with Druva on port 443. The communication is outbound only and you need to create an outbound traffic rule. The backup proxy also communicates with the vCenter on port 443 to understand the VMware hierarchy and communicates with the virtual machines to perform backups and restores.
Features of the Backup Solution
| What backup repositories are supported? | AWS S3 |
| How is backup data transmitted to the repository? | DX, Public Internet |
| Describe the implementation of the Datamover component |
|
| Datamover Scale |
|
| In large SDDCs (>500 VMs, >nTBs), your solution may scale data movers. How do you scale? |
|
| How are additional data movers provisioned? | Customer controlled |
| Describe additional functionalities of image-based backups |
|
| Describe if in-guest backup options are available | Agentless, application-aware backup capabilities for Microsoft SQL databases inside the virtual machine. Administrators can perform granular recovery of Microsoft SQL databases. |
| Describe security features |
|
| Describe network bandwidth/utilization control features | Configurable bandwidth |
| Describe design of deduplication/compression features | Source Side (VMC) data is processed at the backup proxy end for deduplication wherein, the deduplicated data is then sent to the Phoenix Cloud. |
| Describe added-value services/features not listed above |
|
For a 1TB VM Full backup/Full restore, describe
| Full backup/Full restore takes approximately 2 hours to complete. The network bandwidth usage depends on the amount of data that can be compressed and deduplicated. Typically, a 500 Mbps pipe is required for an on-Premise environment. |
| Hybrid centralized management: Describe how on-premises and VMC backups can be managed. Do you support single management console? |
|
Hybrid restore/migration mode: Describe how a VM can be restored from on-premises backup to VMC or from VMC to on-premises | The target repository for both--On-Premise / VMC remains the same i.e Druva storage (S3).
|
| For example, let’s say that you have a hybrid configuration. On-premise with local backup, in VMC with cloud backup. What happens if an on-premise VM is migrated to VMC? Will the backup solution automatically update the location of the repository or will the VM still be backed up on premise? | Since our backup repository is in AWS i.e. the data always gets backed up to S3, whether the VM resides in an On-Premise VMware infrastructure or VMC doesn’t really matter to us. The customer will get the benefit of deduplication. The backup solution will not automatically update the repository, but the VM will continue to be backed up to AWS. If the VM was being backed up to the optional CloudCache component, the component since it won’t be reachable from the VMC, the VM will automatically fallback to back up directly to AWS. |
| Scale: a. What are your supported maximums (# of VMs, # of TBs) both in number, and/or in simultaneous backup streams? b. Given your SLA, then what is the max bandwidth between VMC and repository? | There is no limit for the number of virtual machines or amount of data that can be backed up. By default, a single proxy can process 3 virtual concurrently. The deployment can be either scaled up or scaled out depending on requirements. |
Support Information
Feedback
Yes
No
Powered by
