[VMC on AWS] 2 Node SDDC vMotion triggering the HA Insufficient resources alert.
Article ID: 320325
Updated On:
Products
VMware Cloud on AWS
Issue/Introduction
This article will explain why this occurs more often in the 2 node SDDC and considerations when choosing to use the 2 node SDDC.
Symptoms:
When performing vMotion migration to the 2 node VMC SDDC the HA alert stating that there is not enough resources available will be triggered.
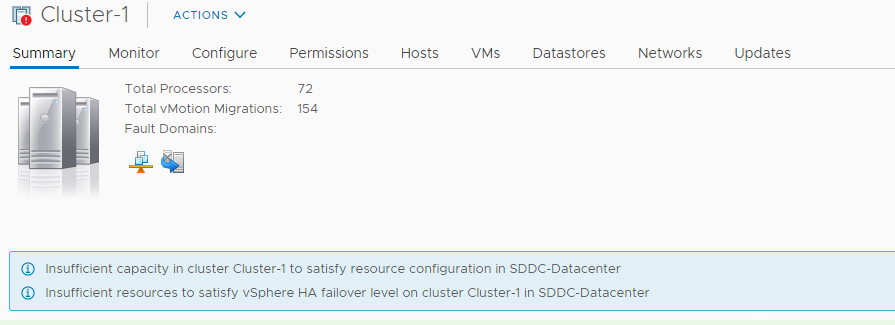
Symptoms:
When performing vMotion migration to the 2 node VMC SDDC the HA alert stating that there is not enough resources available will be triggered.
Cause
The 2 node SDDC used with the VMC on AWS product has to consider the service level agreement(SLA). The SLA states that in the event of a host failure all virtual machines must be able to reside on the remaining host. The HA reservation therefore will be set to 50% in the admission Control for both the CPU capacity and memory capacity. This implies that each host has only half of those resource available to support the population of virtual machines placed on that single host. This will also be consumed by the management virtual machines necessary to support the SDDC such as vCenter appliance, and add on such as HCX appliances. The management appliance will consume a portion of that 50% of capacity left for the workload placed on the host.
When vMotion is used to migrate a virtual machine the vMotion protocol will use a 2.5x CPU multiplier during the migration. Once the migration is completed the reservation is relaxed.
Example:
In a 2 node cluster as mentioned in the previous updates, there is very minimal cpu reservation(1151 MHz) available for the VMs. When there are no active vMotion tasks, the advertised cpu capacity from each host is 74719 MHz. Looking at the host-sync updates during the relocate task
Only during the migration are they different. Host 3020 is the destination of the vMotion migration. The VM is being given a reservation of 2.5x CPU. This is then subtracted from the total available CPU resource which leaves us with less than 50% available to satisfy the Admission control reservation during the vMotion process. Once the vMotion completes the 2.5x CPU reservation is lifted and the alert will clear. During the time that the alert is active no VM can be reboot or created. Admission control will prevent it due to the lack of CPU resources available. This alert should clear after approximately 30 minutes, but can be manually cleared.
When vMotion is used to migrate a virtual machine the vMotion protocol will use a 2.5x CPU multiplier during the migration. Once the migration is completed the reservation is relaxed.
Example:
In a 2 node cluster as mentioned in the previous updates, there is very minimal cpu reservation(1151 MHz) available for the VMs. When there are no active vMotion tasks, the advertised cpu capacity from each host is 74719 MHz. Looking at the host-sync updates during the relocate task
Migration triggered with destination host set to host-3020
info vpxd[59282] [opID=82149-TxId: ..b8-01] [VpxLRO] -- BEGIN lro-16906477 -- vm-3119 -- vim.VirtualMachine.relocate
verbose vpxd[59282] [opID=82149-TxId:..b8-01] Workflow context:
--> (vpx.vmprov.MigrateContext) {
--> spec = (vim.vm.RelocateSpec) {
...
--> host = 'vim.HostSystem:<UUID_#>:host-3020',
While the vMotion is in progress, vpxd receives updated cpu capacity from the host via host-sync
verbose vpxd[49126] [opID=HB-host-3020@269689-76ded28e] [vim.HostSystem:host-3020,<IP>]: cpuCapacity=68969 memCapacity=462622
If HA computes the total cluster capacity at this point, it will be
74719(host-1241) + 68969(host-3020) = 143688 MHz. <=== Note that Host 3020 has less CPU than host-1241
This drop in the available capacity of host-3020 is resulting in InsufficientFailoverResourcesEvent event to be triggered
vMotion fails and host advertised cpu capacity is back to 74819 MHz
verbose vpxd[49164] [opID=82149-TxId..] [vim.HostSystem:host-3020,<IP>]: cpuCapacity=74719 <==Note here that CPU capacity is now reported higher
memCapacity=462618
info vpxd[59282] [opID=82149-TxId:..b8-01] [VpxLRO] -- ERROR lro-16906477 -- vm-3119 -- vim.VirtualMachine.relocate: vmodl.fault.SystemError:
As we can see both of these host prior to the migration and after the migration failure have the same CPU capacity of 74719 Mhz.info vpxd[59282] [opID=82149-TxId: ..b8-01] [VpxLRO] -- BEGIN lro-16906477 -- vm-3119 -- vim.VirtualMachine.relocate
verbose vpxd[59282] [opID=82149-TxId:..b8-01] Workflow context:
--> (vpx.vmprov.MigrateContext) {
--> spec = (vim.vm.RelocateSpec) {
...
--> host = 'vim.HostSystem:<UUID_#>:host-3020',
While the vMotion is in progress, vpxd receives updated cpu capacity from the host via host-sync
verbose vpxd[49126] [opID=HB-host-3020@269689-76ded28e] [vim.HostSystem:host-3020,<IP>]: cpuCapacity=68969 memCapacity=462622
If HA computes the total cluster capacity at this point, it will be
74719(host-1241) + 68969(host-3020) = 143688 MHz. <=== Note that Host 3020 has less CPU than host-1241
This drop in the available capacity of host-3020 is resulting in InsufficientFailoverResourcesEvent event to be triggered
vMotion fails and host advertised cpu capacity is back to 74819 MHz
verbose vpxd[49164] [opID=82149-TxId..] [vim.HostSystem:host-3020,<IP>]: cpuCapacity=74719 <==Note here that CPU capacity is now reported higher
memCapacity=462618
info vpxd[59282] [opID=82149-TxId:..b8-01] [VpxLRO] -- ERROR lro-16906477 -- vm-3119 -- vim.VirtualMachine.relocate: vmodl.fault.SystemError:
Only during the migration are they different. Host 3020 is the destination of the vMotion migration. The VM is being given a reservation of 2.5x CPU. This is then subtracted from the total available CPU resource which leaves us with less than 50% available to satisfy the Admission control reservation during the vMotion process. Once the vMotion completes the 2.5x CPU reservation is lifted and the alert will clear. During the time that the alert is active no VM can be reboot or created. Admission control will prevent it due to the lack of CPU resources available. This alert should clear after approximately 30 minutes, but can be manually cleared.
Resolution
There is no resolution for this issue with vMotion migrations. This only occurs with vMotion migrations in the 2 node cluster.
Workaround:
The alternative is to use bulk migration. The bulk migration does not use the vMotion protocol and therefore does not include the 2.5x reservation of CPU that vMotion does.
Workaround:
The alternative is to use bulk migration. The bulk migration does not use the vMotion protocol and therefore does not include the 2.5x reservation of CPU that vMotion does.
Additional Information
Impact/Risks:
DRS and HCX vMotion migration may cause the insufficient resources alert to be triggered. The could potentially cause the creation of new virtual machines or the power up of an existing virtual machine to fail until the alert is cleared.
DRS and HCX vMotion migration may cause the insufficient resources alert to be triggered. The could potentially cause the creation of new virtual machines or the power up of an existing virtual machine to fail until the alert is cleared.
Feedback
Yes
No
Powered by
