VDS IPFIX performance with NSX-V and vRNI
Article ID: 314383
Updated On:
Products
VMware Aria Operations for Networks
VMware NSX
Issue/Introduction
This document is meant to show the impact of enabling VDS IPFIX in an environment running NSX-V 6.4.5 and ESXI 6.5U3+ or 6.7U2+.
Note: VDS IPFIX is enabled for customers running vRNI under the vCenter data source when the box "Enable NetFlow (IPFIX) on this vCenter" is ticked.
Build info
NSX-V 6.4.5 (11812134)
ESX 6.8 (11761752)
Testbed info
2 Dell PowerEdge R630 servers:
Each server has ESXi 6.8 installed. There are 8 VMs (2vCPUs per VM) on each server. VM on ESXI1 sends traffic to another VM on ESXI2, which are connected via a Switch. We have :
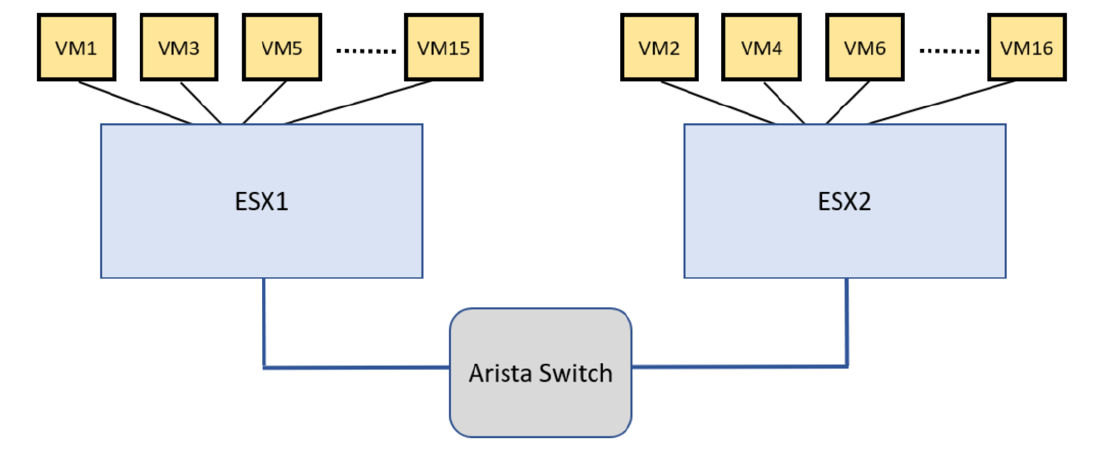
VMs are using Ubuntu 14 with kernel : 3.13.0-43-generic #72-Ubuntu SMP Mon Dec 8 19:35:06 UTC 2014
The logical topology is L2 with overlay: 16 VMs attached to the same logical switch. Overlay is configured between ESXI1 and ESXI2. Test traffic is sent across the network.
We use netperf to generate traffic between VMs. The following types of tests for different purpose:
To see the impact of IPFIX, we run all the above tests in 3 sets of configurations, shown in the following table. Each configuration has its own label, which is used later in the graphs.
Note: vRNI does automatically configure bi-directional IPFIX from version 5.2. You must run ESXI 6.5U3+ or 6.7U2+ to leverage bi-directional IPFIX.
Background traffic is generated by nmap's basic TCP SYN Scan. We generated 5k bi-directional flows. Just by enabling the nmap script, we see ~26% CPU usage on each ESXI.
For the remaining configuration, we changed the RSS setting of the NIC to enable 4RX queues.
Below the performance impact of IPFIX :
Packet rate
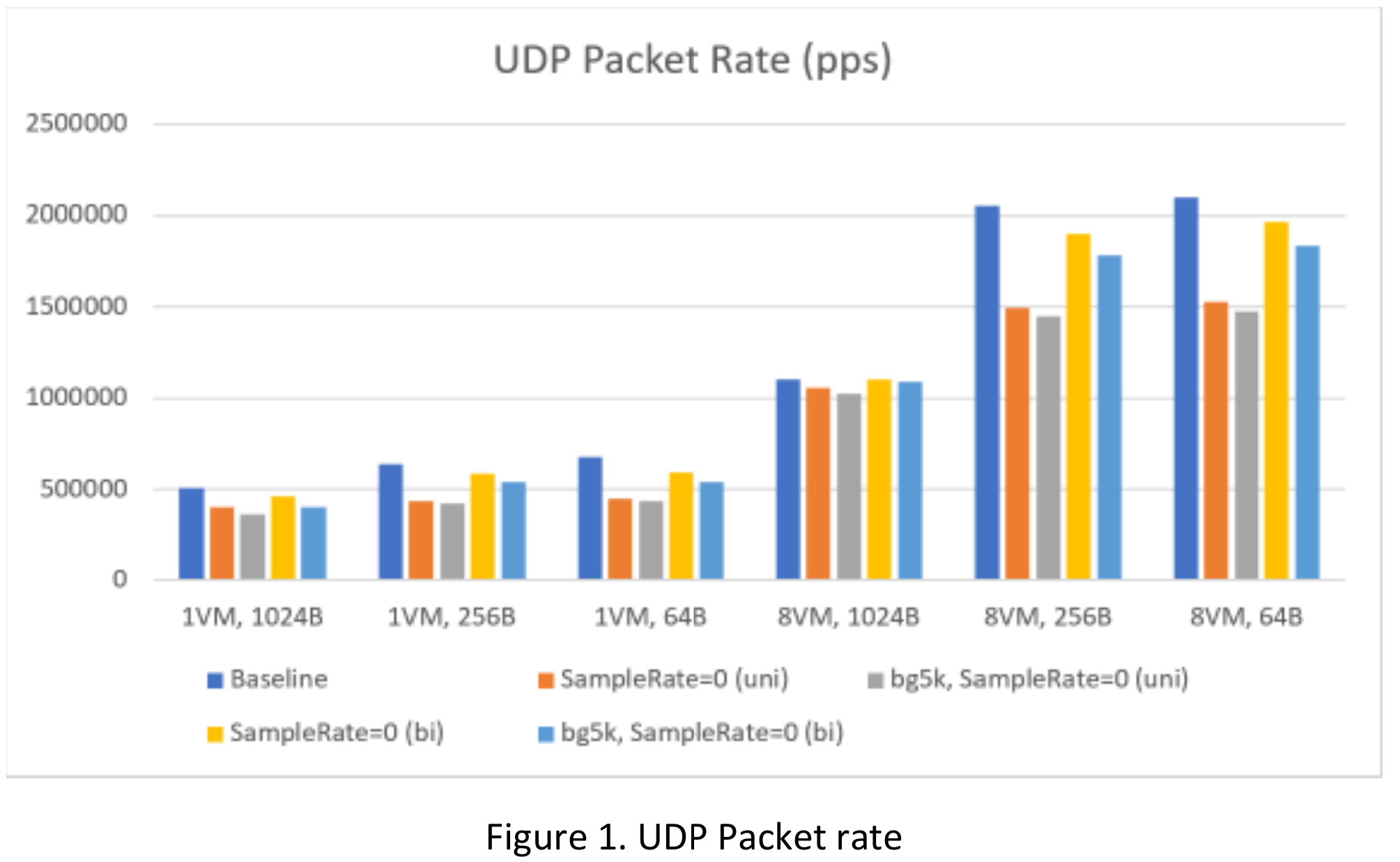
From Figure 1, we can see :
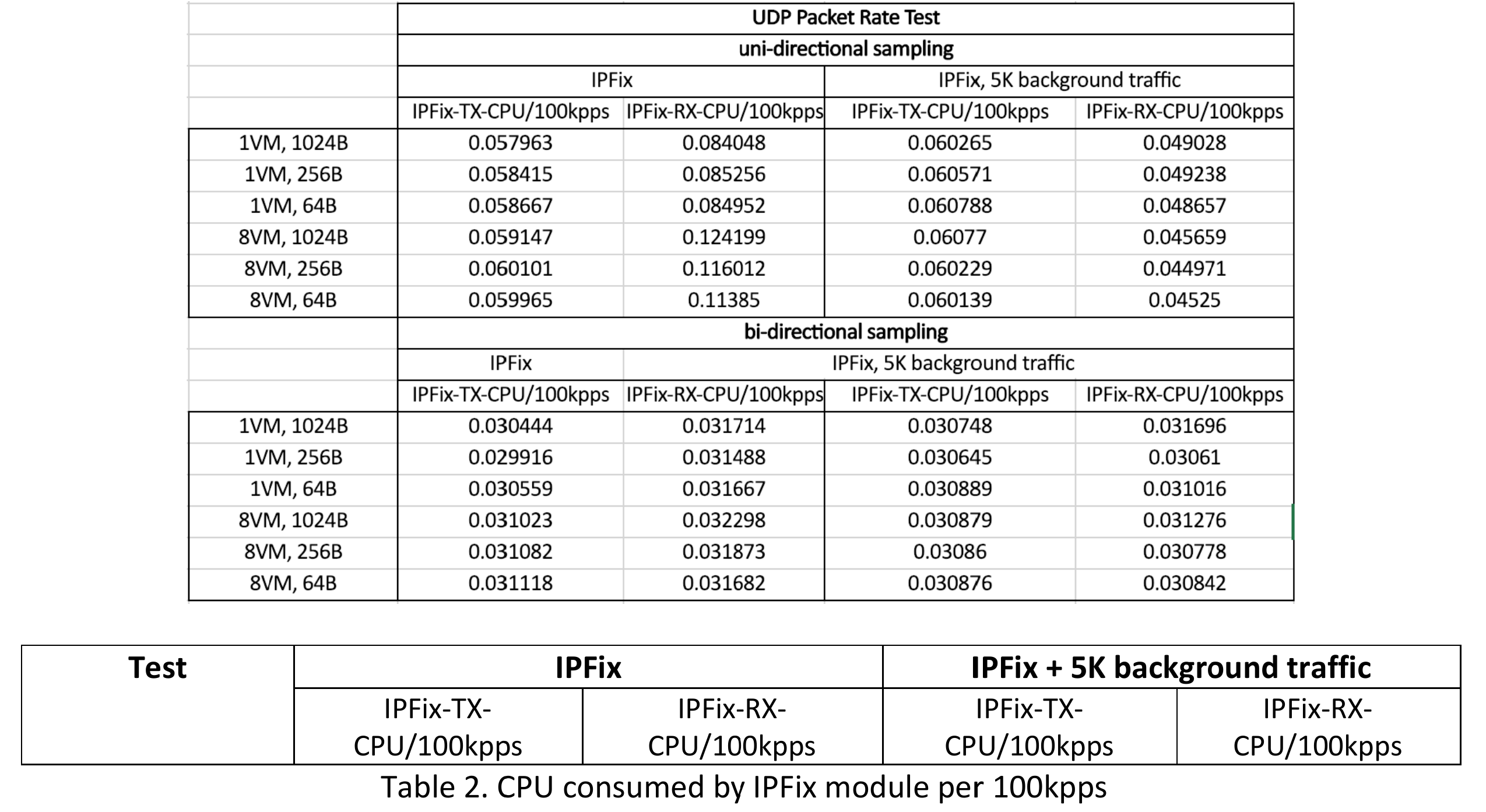
We also observe higher CPU consumption after IPFIX is enabled. Since we focus on the cost of IPFIX, in the following table, we will show the CPU spent on IPFIX module for every 100 kpps on both TX and RX side.
Transaction rate
TCP_CRR is used for TCP transaction rate measurement. It creates a new TCP connection for every transaction, simulating the behavior of HTTP. Due to the flow-based feature, transaction rate is an important performance metric for IPFIX.
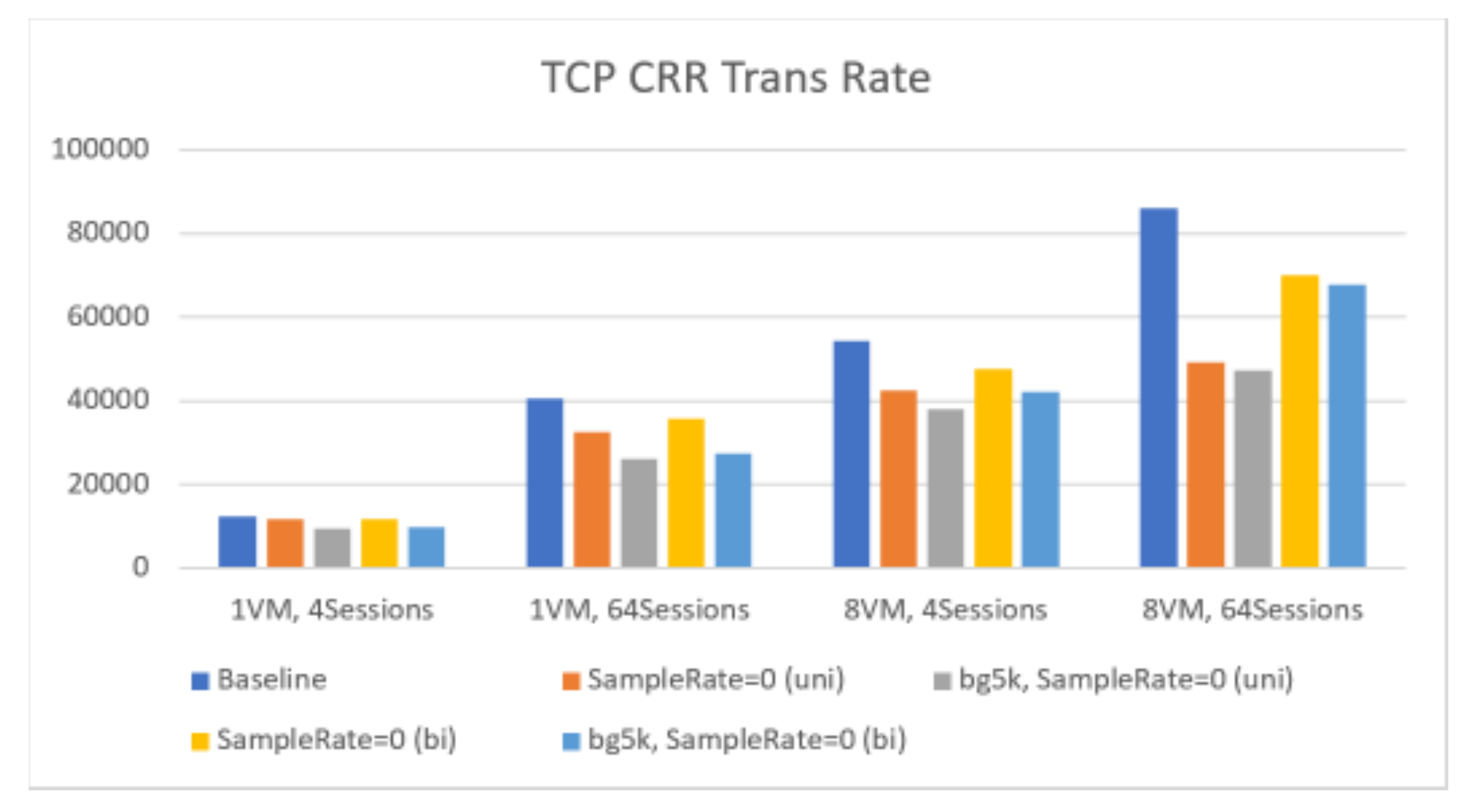
Figure 2. Transaction Rate comparison
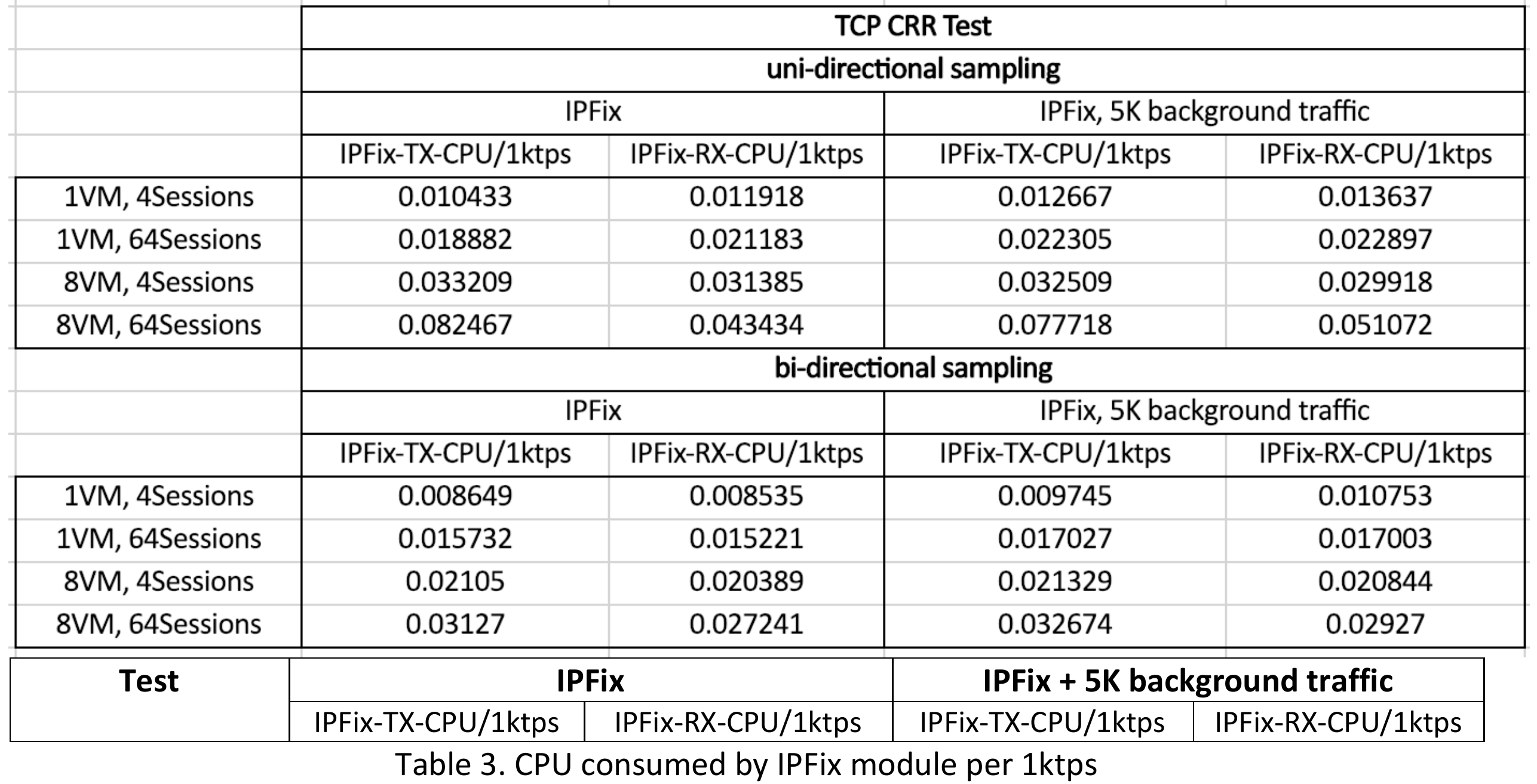
From Figure 2 and Table 3, we observe :
Throughput
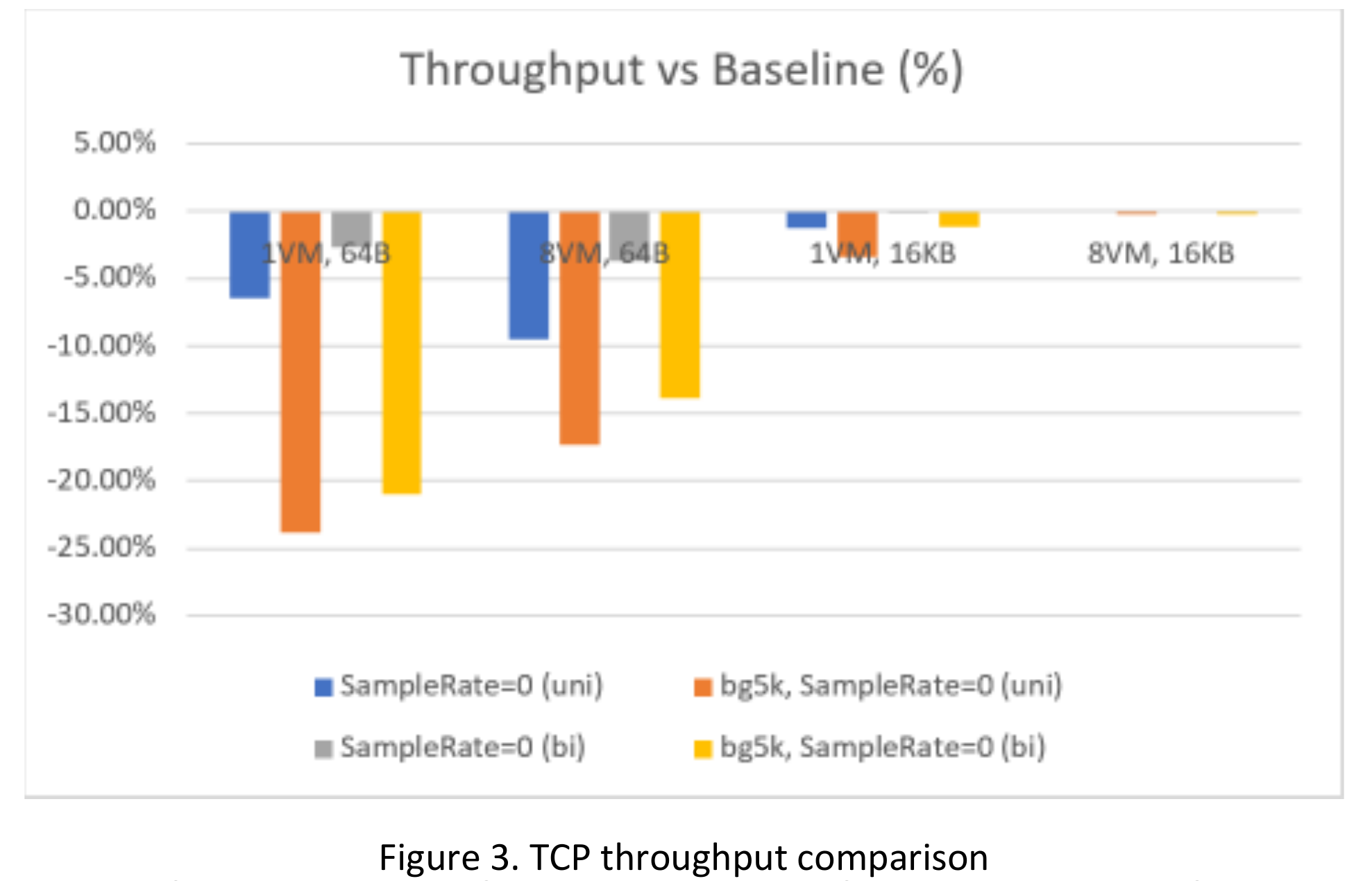
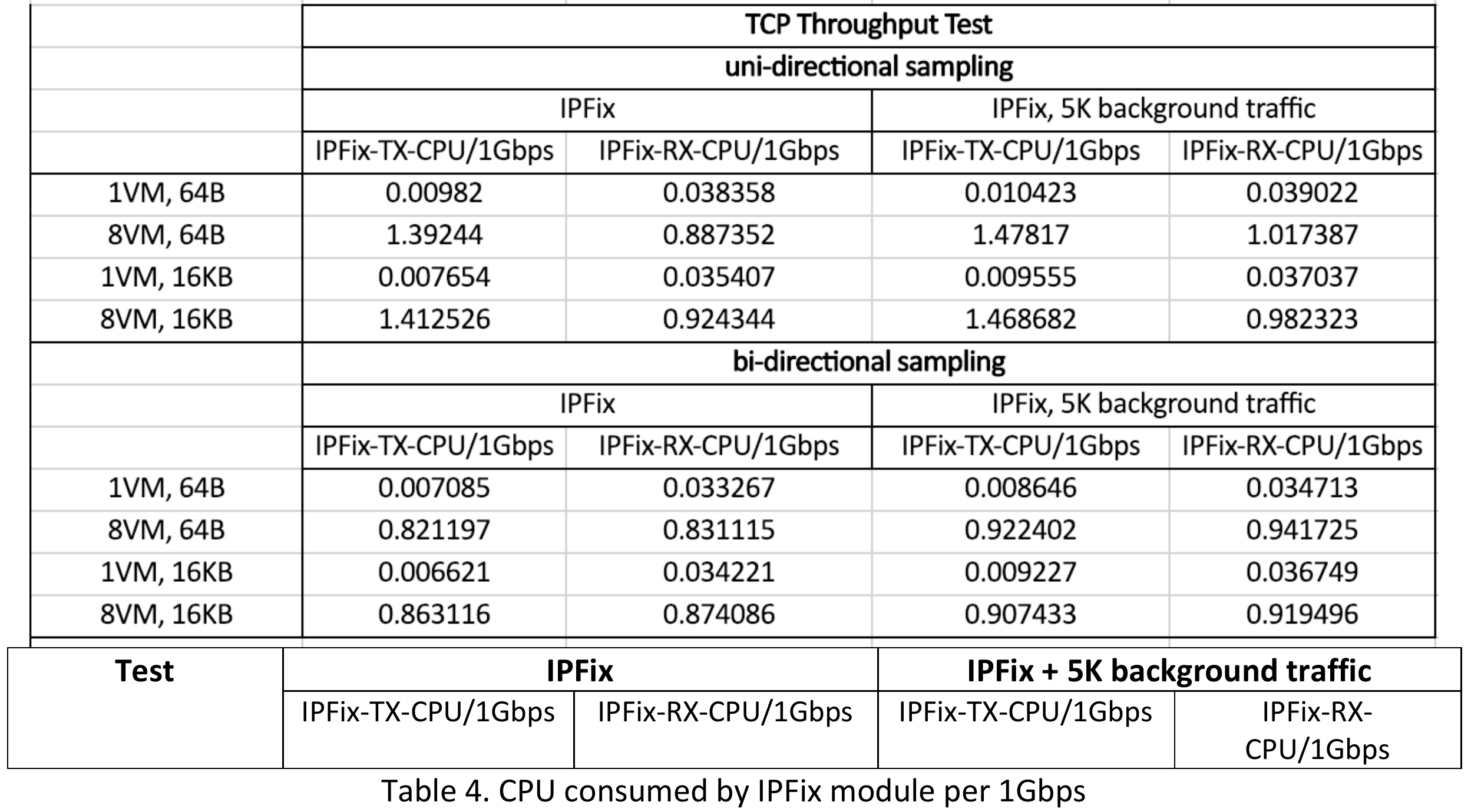
From Figure 3 and Table 4, we can see :
For optimal performance, we recommend to run ESXI 6.5U3+ or 6.7U2+ with vRNI 5.2 to leverage bi-directional IPFIX.
Note: VDS IPFIX is enabled for customers running vRNI under the vCenter data source when the box "Enable NetFlow (IPFIX) on this vCenter" is ticked.
Build info
NSX-V 6.4.5 (11812134)
ESX 6.8 (11761752)
Testbed info
2 Dell PowerEdge R630 servers:
- 24 cores (2 NUMA nodes, 12 cores per NUMA)
- CPU: Intel (R) Xeon (R) CPU E5-2690 v3 @ 2.60GHz
- Memory size = 275 GB
- NIC : Intel X540
- driver : ixgbe
- version : 3.7.13.7.14iov-NAPI
- firmware-version : 0x800005a0
Each server has ESXi 6.8 installed. There are 8 VMs (2vCPUs per VM) on each server. VM on ESXI1 sends traffic to another VM on ESXI2, which are connected via a Switch. We have :
- 1 VM-pair test for vNIC performance
- 8 VM-pair tests for whole system performance
VMs are using Ubuntu 14 with kernel : 3.13.0-43-generic #72-Ubuntu SMP Mon Dec 8 19:35:06 UTC 2014
The logical topology is L2 with overlay: 16 VMs attached to the same logical switch. Overlay is configured between ESXI1 and ESXI2. Test traffic is sent across the network.
We use netperf to generate traffic between VMs. The following types of tests for different purpose:
- UDP_STREAM: for packet rate
- TCP_CRR: for transaction rate
- TCP_STREAM: for throughput
To see the impact of IPFIX, we run all the above tests in 3 sets of configurations, shown in the following table. Each configuration has its own label, which is used later in the graphs.
| Configuration / Label | Note |
| Baseline (Baseline) | IPFIX disabled (L2.vxlan) |
| IPFIX enabled (IPFIX) | With sample rate 0 on both uplink and vnics |
| IPFIX enabled with background traffic (IPFIX+5k flow)With | With sample rate 0 on both uplink and vnics Background traffic : 5k bidirection TCP flows |
| Bi-directional IPFIX enabled (IPFIX-bi) | With sample rate 0 on vnics and bi-directional sampling |
| Bi-directional IPFIX enabled with background traffic (IPFIX + 5k flows bi) | With sample rate 0 on vnics and bi-directional sampling Background traffic : 5k bidirectional TCP flows |
Note: vRNI does automatically configure bi-directional IPFIX from version 5.2. You must run ESXI 6.5U3+ or 6.7U2+ to leverage bi-directional IPFIX.
Background traffic is generated by nmap's basic TCP SYN Scan. We generated 5k bi-directional flows. Just by enabling the nmap script, we see ~26% CPU usage on each ESXI.
For the remaining configuration, we changed the RSS setting of the NIC to enable 4RX queues.
Below the performance impact of IPFIX :
Packet rate
From Figure 1, we can see :
- For a single vNIC, depending on the packet size, packet rate is 20/30% lower after uni-directional IPFIX is enabled; with 5k background traffic, it would be an additional 2-8% degradation. If bi-directional sampling is enabled, packet rate is 6-12% lower; with 5k background traffic, it could be another 2-9% lower.
- For the whole system, before IPFIX is enabled, max packet rate is ~2mpps. After uni-directional IPFIX is enabled, max packet rate drops to ~1.5mpps uni-directional, and to ~1.8 mpps for bi-directional sampling
- IPFIX has more impact on smaller packets.
We also observe higher CPU consumption after IPFIX is enabled. Since we focus on the cost of IPFIX, in the following table, we will show the CPU spent on IPFIX module for every 100 kpps on both TX and RX side.

From above table, we see some CPU increase caused by IPFIX:
From above table, we see some CPU increase caused by IPFIX:
- For 1 VM test (single vNIC), for every 100 kpps (packet size independent), IPFIX module costs ~0.058 CPU core on TX and ~0.084 CPU core on RX; adding 5k background traffic, the CPU cost is ~0.06 CPU core on TX and 0.049 on RX side.
Transaction rate
TCP_CRR is used for TCP transaction rate measurement. It creates a new TCP connection for every transaction, simulating the behavior of HTTP. Due to the flow-based feature, transaction rate is an important performance metric for IPFIX.
Figure 2. Transaction Rate comparison
From Figure 2 and Table 3, we observe :
- After enabling IPFIX, transaction rate could drop 20-42%, if 5k background traffic is enabled, it shows additional 2-10% drop.
- The max transaction rate is ~86ktps without IPFIX. After enabling IPFIX, it is ~49ktps.
- To understand Table 3's content, let's take the first entry as one example. It means that for every 1000 transactions per second (1ktps), 1 VM with 4 TCP_CRR sessions, IPFIX module costs 0.0104 CPU core on TX and 0.0119 CPU core on RX.
- From Table 3, IPFIX shows scalability issue. It may have potential contention.
Throughput
From Figure 3 and Table 4, we can see :
- When sending large TCP message (16KB), throughput can reach line rate, or close to line rate even with IPFIX enabled.
For optimal performance, we recommend to run ESXI 6.5U3+ or 6.7U2+ with vRNI 5.2 to leverage bi-directional IPFIX.
Feedback
Yes
No
Powered by
