VMware vSphere support with NetApp MetroCluster.
Article ID: 312183
Updated On:
Products
Issue/Introduction
Additional storage may be provisioned from the NetApp MetroCluster Solution for in-guest applications, either as file-based storage, or using in-guest iSCSI initiators.
Note: The PVSP policy implies that the solution is not directly supported by VMware. For issues with this configuration, contact NetApp Inc directly. See the Support Workflow on how partners can engage with VMware. It is the partner's responsibility to verify that the configuration functions with future vSphere major and minor releases, as VMware does not guarantee that compatibility with future releases is maintained.
Disclaimer: The partner products referenced in this article are developed and supported by a partner. The use of these products is also governed by the end-user license agreements of the partner. You must obtain the storage system, support, and licensing for using these products from the partner.
For more information, see:
• NeApp Home Page
• NetApp Support Site
Environment
VMware vSphere ESXi 7.x
VMware vSphere ESXi 8.x
Resolution
What is vMSC?
A VMware vSphere Metro Storage Cluster configuration is a VMware vSphere certified solution that combines synchronous replication with array-based clustering. These solutions are implemented with the goal of reaping the same benefits that high-availability clusters provide to a local site, but in a geographically dispersed model with separate failure domains. At its core, a VMware vMSC infrastructure is a stretched cluster. The architecture is built on the idea of extending what is defined as local in terms of network and storage. This enables these subsystems to span geographies, presenting a single and common base infrastructure set of resources to the vSphere cluster at both sites. It stretches network and storage between sites. All supported storage devices are listed on the VMware Storage Compatibility Guide.What is a NetApp MetroCluster™?
NetApp MetroCluster is a high-availability solution that ensures continuous data availability and protection in enterprise environments. It combines multiple NetApp storage systems, including NetApp ASA (A-series), AFF (A-Series, C-Series), and FAS family of storage systems, into a single cluster. By synchronously mirroring data between nodes, MetroCluster achieves zero data loss and seamless failover. This guarantees business continuity, minimizes downtime, and safeguards critical applications and data against disruptions caused by natural disasters, hardware failures, or planned maintenance. MetroCluster runs on various models of NetApp hardware and enhances the built-in high availability and nondisruptive operations provided by NetApp ONTAP storage software. It simplifies administration, eliminates the complexities of host-based clustering, and immediately duplicates mission-critical data on a transaction-by-transaction basis, ensuring uninterrupted access to applications and data. Unlike standard data replication solutions, MetroCluster seamlessly integrates with the host environment, providing continuous data availability without the need for complicated failover scripts. It effectively maintains application availability, whether the environment consists of standalone servers, high-availability server clusters, or virtualized servers. MetroCluster's array-based active-active clustered solution eliminates the need for complex failover scripts, server reboots, or application restarts, resulting in minimal application interruption during cluster recovery.Figure 1) NetApp MetroCluster Architecture
What are the Metrocluster Deployment Options?
NetApp MetroCluster offers a range of deployment options to ensure data redundancy and continuous availability. MetroCluster is a fully redundant configuration that requires identical hardware at each site. It provides flexibility of stretch, fabric-attached (FC), and IP configurations, allowing organizations to choose the option that best suits their needs.
What are the fabric-attached (FC) architectures?
Metrocluster configurations utilizing fabric-attached storage architectures include stretch, stretched-bridged, and fabric-attached (FC) configurations. The fabric-attached configuration utilizes Fibre Channel technology for synchronous replication between two sites. Supported on AFF, ASA, and FAS platforms and can be deployed in two-, four-, and eight-node architectures. This configuration requires an FC back-end storage fabric, SAS bridges per site per disk shelf stack, and can be switchless or use switched clusters. It offers a lower cost 2-node configuration.
Figure 2) Sample MetroCluster FC Architecture.
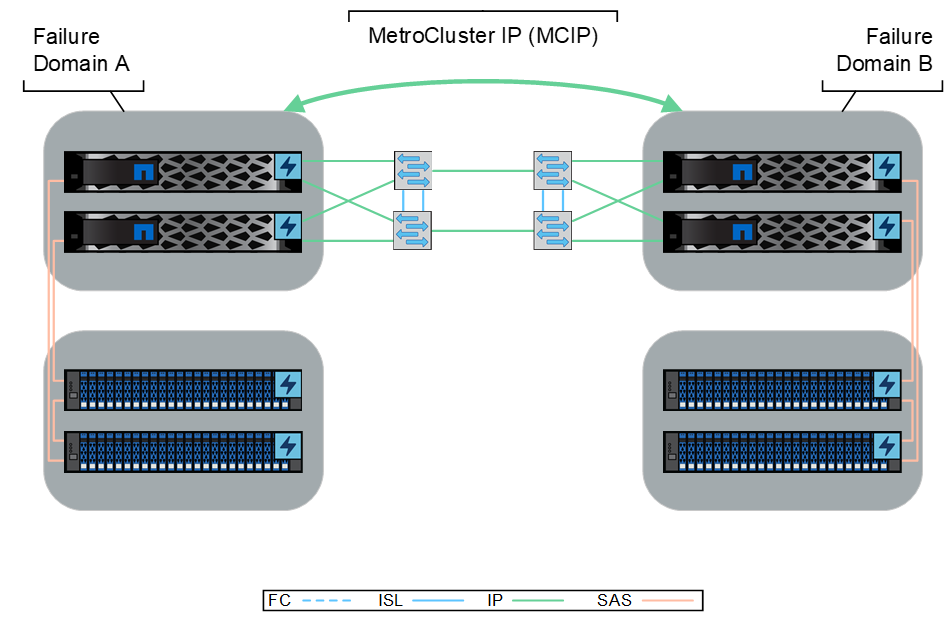
What is the ethernet (IP) architecture?
The IP configuration of MetroCluster utilizes IP networks for synchronous replication between two sites. Supported on AFF, ASA, and FAS platforms, MetroCluster IP can be deployed in four- and eight-node architectures. It requires an Ethernet back-end storage fabric, switched clusters with dedicated NetApp-provided switches, and the use of MetroCluster Tiebreaker or ONTAP Mediator. This configuration provides flexibility and is suitable for larger distance deployments.
Figure 3) Sample MetroCluster IP Architecture.
What is a quorum witness?
A quorum witness is essential in storage clusters to maintain high availability, prevent data corruption, and facilitate failover and recovery. By acting as a tiebreaker and ensuring nodes can communicate with each other, the quorum witness helps avoid split-brain scenarios, where cluster nodes operate independently, leading to data inconsistencies. MetroCluster IP supports both MetroCluster Tiebreaker and ONTAP Mediator, while MetroCluster FC supports only the MetroCluster tiebreaker. The quorum witness should be hosted in a third failure domain, separate from the two ONTAP clusters forming the MetroCluster, and is required to establish consensus across the three-party quorum:
2. Secondary MetroCluster nodes.
3. ONTAP Mediator or NetApp Tiebreaker
What is ONTAP Mediator?
ONTAP Mediator is a component of NetApp's ONTAP software, specifically designed to support MetroCluster configurations. It acts as a participant om the quorum to help establish consensus in situations where network partitions or node failures occur. The Mediator plays a crucial role in determining which set of nodes should continue functioning as the active cluster, ensuring data consistency, and preventing split-brain scenarios. Additionally, ONTAP Mediator supports Automatic Unplanned Switchover (AUSO), which enables seamless failover of storage resources between nodes in a MetroCluster setup. AUSO enhances the resiliency and availability of MetroCluster deployments by automating the process of redirecting storage operations to alternate nodes. This ensures continuous data access and minimizes disruptions in critical enterprise environments.What is MetroCluster Tiebreaker?
NetApp MetroCluster Tiebreaker software checks the reachability of the nodes in a MetroCluster configuration and the cluster to determine whether a site failure has occurred. The Tiebreaker software also triggers an alert under certain conditions. The Tiebreaker software runs on a RHEL physical or virtualized servers, and it is best deployed at a third failure domain for independent visibility to all MetroCluster nodes.The Tiebreaker software monitors each controller in the MetroCluster configuration by establishing redundant connections through multiple paths to a node management LIF and to the cluster management LIF, both hosted on the IP network.
The Tiebreaker software monitors the following components in the MetroCluster configuration:
• Cluster through the cluster-designated interfaces
• Surviving cluster to evaluate whether it has connectivity to the disaster site (FCVI, storage, and intercluster peering)
Automatic Unplanned Switchover in MetroCluster
In a MetroCluster configuration, the system can perform an automatic unplanned switchover (AUSO) in the event of a site failure to provide nondisruptive operations.In a four-node and eight-node MetroCluster configuration, an AUSO can be triggered if all nodes at a site are failed because of the following reasons:
• Node power loss
• Node panic
• Node power loss
• Node panic
• Node reboot
Automatic healing after an unscheduled switchover is available for MetroCluster IP configurations starting from ONTAP 9.6. However, for MetroCluster FC configurations, automatic healing is not supported. On MetroCluster IP configurations running ONTAP 9.5 and earlier, manual healing commands are still necessary after an unscheduled switchover.
Configuring MetroCluster
MetroCluster is a combined hardware and software solution, with deployment flexibility including 2-nodes to 8-nodes options. Specific hardware is required to create the shared storage fabric and inter-site links. Consult the NetApp Interoperability Matrix (IMT) and the NetApp Hardware Universe for supported hardware. On the software side, MetroCluster is completely integrated into Data ONTAP - no tools or licenses are required to leverage MetroCluster. Once the MetroCluster relationships are established, data and configuration are automatically and continuously replicated between the sites. There is no need for manual intervention to replicate newly provisioned workloads. This streamlined process simplifies administration and eliminates the risk of inadvertently forgetting to replicate critical workloads.These requirements must be satisfied to support this configuration:
- MetroCluster comes bundled with ONTAP, thus nullifying additional license expenditures. However, licenses are necessary for protocols and additional features used within the cluster. It is important to ensure symmetrical licensing across both sites. For example, if SMB or SnapMirror are utilized, they must be licensed in both clusters. Switchover operations require matching licenses on both sites to function properly.
- All nodes should be licensed for the same node-locked features.
- All 4 nodes in a DR group must be the same model ASA, AFF, or FAS (for example, four ASA A400 or four FAS9500).
- Network quality between failure domains requires round trip time latency to be less than 10ms. Current qualified distances for MetroCluster FC (300 km) and MetroCluster IP (700 km) can be extended by request for networks meeting requirements.
- The storage network must have a minimum of 4Gbps throughput between the two sites for ISL connectivity, refer to NetApp’s IMT tool for specific controller and minimum ISL requirements.
- For NFS/iSCSI configurations, a minimum of two uplinks for the controllers must be used. An interface group (ifgroup) should be created using the two uplinks in multimode configurations.
- The VMware datastores and NFS volumes configured for the ESX servers are provisioned on mirrored aggregates.
- ESXi hosts in the vMSC configuration should be configured with at least two different IP networks, one for storage and the other for management and virtual machine traffic. The Storage network handles NFS and iSCSI traffic between ESXi hosts and NetApp Controllers. The second network (VM Network) supports virtual machine traffic as well as management functions for the ESXi hosts. End users can choose to configure additional networks for other functionality such as vMotion/Fault Tolerance. While not a strict requirement, it is highly recommended to follow this as a best practice for a vMSC (Virtual Storage Area Network [VSAN] Metro Storage Cluster) configuration.
- FC Switches are utilized for vMSC configurations where datastores are accessed through FC protocols. ESXi management traffic is on an IP network. End users also have the option to configure extra networks for other functionalities such as vMotion/Fault Tolerance and guest connectivity.
- For NFS/iSCSI configurations, a minimum of two uplinks for the controllers must be used. An interface group (ifgroup) should be created using the two uplinks in multimode configurations.
- The VMware datastores and NFS volumes configured for the ESX servers are provisioned on mirrored aggregates.
- vCenter Server must be able to connect to ESX servers on both sites.
- The maximum number of Hosts in an HA cluster must not exceed 32 hosts.
- It is required to deploy a quorum witness (MetroCluster Tiebreaker, ONTAP Mediator) in a third failure domain. The quorum witness should have the capability to access the storage controllers in both failure domain A and failure domain B. This ensures that in the event of a complete site failure, the quorum witness can participate in the process to initiate a switchover to maintain continuous operations.
- For more information on NetApp MetroCluster Design and Implementation, see the ONTAP MetroCluster Documentation.
- For information about NetApp and VMware solutions, see Learn about NetApp and VMware Solutions.
- For more information on MetroCluster see the following technical reports:
License
MetroCluster is included in ONTAP. There is no separate chargeable license or feature.
Solution Overview
MetroCluster configurations ensure data protection by utilizing two physically separated clusters that are mirrored in separate failure domains. It is required that the network quality between the failure domains maintains a latency of less than 10ms. Each cluster synchronously mirrors the root and data aggregates. In the event of a disaster at one site, a failover can be initiated either by AUSO or by an administrator. Once the failover is triggered, the mirrored data is seamlessly served from the surviving site. Only in the event of a disaster (or for testing purposes), is a full switchover to the other site required. Switchover, and the corresponding switchback operations transfers the entire clustered workload between the sites.In this figure is an example MetroCluster configuration with two data centers, A and B, separated by a distance of 300km. Dedicated fibre-links are used for ISLs (Inter-Switch Links) between the sites. Each site has a cluster consisting of a 2-node HA pair. For instance, site A has nodes A1 and A2, while site B has nodes B1 and B2. The clusters and sites are connected through two separate networks: the cluster peering network for replicating cluster configuration information and the shared storage fabric, which is an FC (Fibre Channel) connection. The shared storage fabric enables storage and NVRAM (Non-Volatile Random Access Memory) synchronous replication between the two clusters. All controllers have visibility to all the storage resources through this shared storage fabric.
Figure 4) vSphere stretched cluster using NetApp MetroCluster architechture
Note: This illustration is a simplified representation and does not indicate the redundant front-end components, such as Ethernet and fibre channel switches.
The vMSC configuration used in this certification program was configured with Uniform Host Access mode. In this configuration, the ESX hosts from a single site are configured to access storage from both sites.
In cases where RDMs are configured for virtual machines residing on NFS volumes, a separate LUN must be configured to hold the RDM mapping files. Ensure you present this LUN to all the ESX hosts.
vMSC test scenarios
This table outlines vMSC test scenarios:| Scenario | NetApp Controllers Behavior | VMware HA Behavior |
| Controller single path failure | Controller path failover occurs. All LUNs and volumes remain connected. For FC datastores, path failover is triggered from the host and the next available path to the same controller will be active. All ESXi iSCSI/NFS sessions remain active in multimode configurations of two or more network interfaces. |
No impact |
| ESXi single storage path failure | No impact on LUN and volume availability. ESXi storage path fails over to the alternative path. All sessions remain active. | No impact |
| Site 1 or Site 2 single storage node failure | Since there is an HA pair at each site, a failure of one node transparently and automatically triggers failover to the other node. | No impact |
| MCTB VM failure | No impact on LUN and volume availability. All sessions remain active. | No impact |
| MCTB VM single Link failure | No impact Controllers continue to function normally. | No impact |
| Complete Site 1 failure, including ESXi and controller | In the case of a site-wide issue, the MetroCluster switchover operation allows immediate resumption of service by moving storage and client access from the Site 1 cluster to Site 2. The Site 2 partner nodes begin serving data from the mirrored plexes and the sync destination Storage Virtual Machine (SVM). |
Virtual machines on failed Site 1 ESXi nodes fail. HA restarts failed virtual machines on ESXi hosts on Site 2. |
| Complete Site 2 failure, including ESXi and controller | In the case of a site-wide issue, the MetroCluster switchover operation allows immediate resumption of service by moving storage and client access from the Site 2 cluster to Site 1. The Site 1 partner nodes begin serving data from the mirrored plexes and the sync destination Storage Virtual Machine (SVM). | Virtual machines on failed Site 2 ESXi nodes fail. HA restarts failed virtual machines on ESXi hosts on Site 1. |
| Single ESXi failure (shutdown) | No impact. Controllers continue to function normally. | Virtual machines on failed ESXi node fail. HA restarts failed virtual machines on surviving ESXi hosts. |
| Multiple ESXi host management network failure | No impact. Controllers continue to function normally. | A new Primary will be selected within the network partition. Virtual machines will remain running. No need to restart virtual machines. |
| Site 1 and Site 2 simultaneous failure (shutdown) and restoration | Controllers boot up and resync. All LUNs and volumes become available. All iSCSI sessions and FC paths to ESXi hosts are re-established and virtual machines restarted successfully. As a best practice, NetApp controllers should be powered on first and allow the LUNs/volumes to become available before powering on the ESXi hosts. |
No impact |
| ESXi Management network all ISL links failure | No impact to controllers. LUNs and volumes remain available. | If the HA host isolation response is set to Leave Powered On, virtual machines at each site continue to run as storage heartbeat is still active. Partitioned Hosts on site that do not have a Fault Domain Manager elect a new Primary. |
| All Storage ISL Links failure | No Impact to controllers. LUNs and volumes remain available. When the ISL links are back online, the aggregates resync. |
No impact |
| System Manager - Management Server failure | No impact. Controllers continue to function normally. NetApp controllers can be managed using Command Line. |
No impact |
| vCenter Server failure | No impact. Controllers continue to function normally. | No impact on HA. However, the DRS rules cannot be applied. |
Feedback
