NetApp ONTAP with NetApp SnapMirror active sync with VMware vSphere Metro Storage Cluster (vMSC).
Article ID: 312014
Updated On:
Products
Issue/Introduction
This article provides information about deploying a vSphere Metro Storage Cluster (vMSC) across two failure domains while using NetApp SnapMirror active sync as the underlying storage solution. This solution applies only to VMFS datastores. SnapMirror active sync can also protect iSCSI and FCP storage used by guest operating systems, either as RDMs or NPIV devices, or using in-guest iSCSI software initiators.
NetApp ONTAP with NetApp SnapMirror active sync with VMware vSphere Metro Storage Cluster (vMSC) is a Partner Verified and Supported Products (PVSP) solution provided and supported by NetApp Inc. The NetApp solution provides multi-site disaster recovery for VMs, Kubernetes (K8s) pods, and traditional applications that are running on NetApp storage in the VMware vSphere ecosystem.
Note: The PVSP policy implies that the solution is not directly supported by VMware. For issues with this configuration, contact NetApp Inc directly. See the Support Workflow on how partners can engage with VMware. It is the partner's responsibility to verify that the configuration functions with future vSphere major and minor releases, as VMware does not guarantee that compatibility with future releases is maintained.
Disclaimer: The partner products referenced in this article are developed and supported by a partner. The use of these products is also governed by the end-user license agreements of the partner. You must obtain the storage system, support, and licensing for using these products from the partner.
For more information, see:
Environment
VMware vSphere ESXi 8.x
Resolution
Solution Overview
NetApp SnapMirror® active sync leverages an advanced symmetric active-active storage architecture to enhance the inherent high availability and non-disruptive operations of NetApp hardware and ONTAP storage software. This powerful solution provides an additional layer of protection for your entire storage and host environment, ensuring uninterrupted application availability.
SnapMirror active sync seamlessly maintains application availability regardless of your environment's composition, including stand-alone servers, high-availability server clusters, or virtualized servers. It protects against storage outages, array shutdowns, power or cooling failures, network connectivity issues, or operational errors. By combining storage array-based clustering with bi-directional synchronous replication, SnapMirror active sync ensures continuous availability even during a disaster.
With its symmetric active-active storage architecture, SnapMirror active sync delivers continuous availability and zero data loss at a cost-effective price. Managing the array-based cluster becomes simpler as it eliminates the dependencies and complexities associated with host-based clustering. By immediately duplicating mission-critical data, SnapMirror active sync provides uninterrupted access to your applications and data. It seamlessly integrates with your host environment, offering continuous data availability without the need for complex failover scripts.
In the example shown in Figure 1, clustered workloads are protected across failure domains. The clustered workload uses the same volume stretched across the failure domains. The peach paths are ALUA AO (active/optimized) while the green paths are ALUA ANO (Active Non-Optimized) for the workloads.
Figure 1) SnapMirror active sync and vMSC (symmetric active-active)
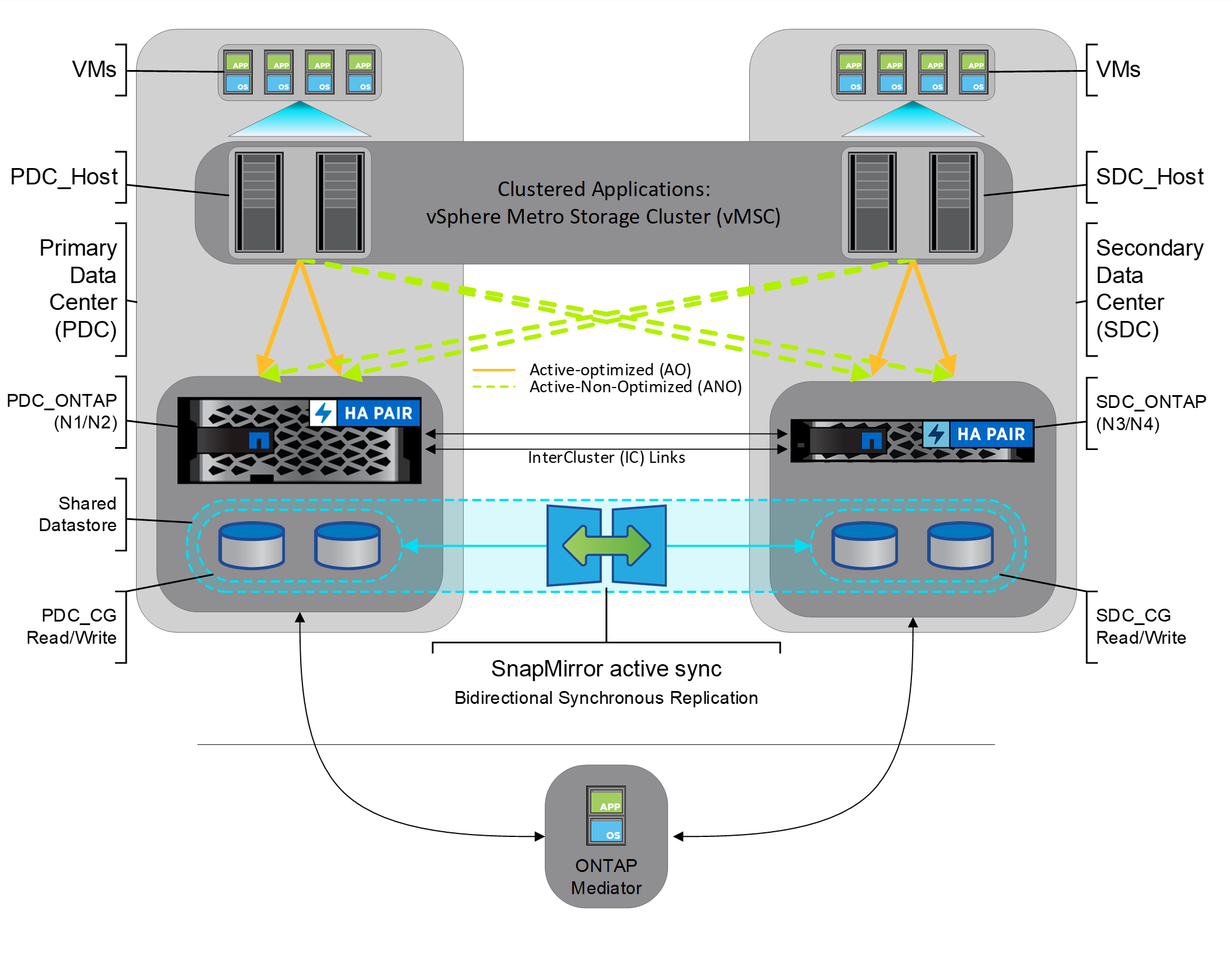
The key features of SnapMirror active sync are:
- Guarantees the protection of SAN applications (iSCSI or FC) across two separate failure domains, ensuring robust business continuity.
- Application focused granularity with intuitive workflows, non-disruptive instantaneous clones, and flexibility of individual application DR tests.
- Transparent application failover of business-critical applications such as Oracle, Microsoft SQL Server, and VMware vSphere Metro Storage Cluster (vMSC)
- Consistency group (CG) ensures dependent write order for a collection for volumes containing application data
- Tight integration with ONTAP leverages robust NetApp technologies to create a highly scalable, enterprise-level data protection solution
- Simplified data management for storage provisioning, host connections, and creation of snapshots and clones for both sites
- Enhanced business continuity by using SnapMirror Asynchronous (SM-A) to create a copy of data at a 3rd failure domain, ensuring long-distance DR and backup support.
What is vMSC?
A VMware vSphere Metro Storage Cluster configuration is a VMware vSphere certified solution that combines synchronous replication with array-based clustering. These solutions are implemented with the goal of reaping the same benefits that high-availability clusters provide to a local site, but in a geographically dispersed model with two locations in separate failure domains. At its core, a VMware vMSC infrastructure is a stretched cluster. The architecture is built on the idea of extending what is defined as local in terms of network and storage. This enables these subsystems to span geographies, presenting a single and common base infrastructure set of resources to the vSphere cluster at both sites. It stretches network and storage between sites. All supported storage devices are listed on the VMware Compatibility Guide .
What is a NetApp® SnapMirror active sync?
Introduced in NetApp ONTAP 9.9.1 SnapMirror® active sync is a business continuity solution for zero recovery point objective (RPO) and zero recovery time objective (RTO). SnapMirror active sync gives you flexibility with easy-to-use application-level granularity and automatic failover. Utilizing SnapMirror synchronous replication technology, SnapMirror active sync ensures fast data replication over IP networks (LAN, WAN) for your enterprise’s business-critical applications. SnapMirror active sync can be deployed with a symmetric active-active configuration in which both failure domains are online and provide simultaneous read/write access to a specific LUN. In this configuration, each LUN is accessible and can be serviced by a controller within each failure domain, ensuring continuous availability and optimal performance. This architecture enhances data mobility, performance, and accessibility by allowing clients to interact with their data at either site without any perceptible disruption, thereby delivering a robust and resilient storage solution that is well-suited for demanding enterprise environments. SnapMirror active sync’s symmetric active-active architecture integrates seamlessly with critical infrastructure services such as VMware vSphere, and key applications such as Oracle and Microsoft SQL Server in both virtual and physical environments. SnapMirror active sync ensures uninterrupted operation of mission-critical business services even in the event of a complete site failure. The solution incorporates Transparent Application Failover (TAF) capabilities, enabling automatic switchover of primary paths to the mirror copy without the need for manual intervention. This streamlined process eliminates the requirement for additional scripting, simplifying disaster recovery and ensuring seamless continuity of operations.
What is ONTAP Mediator ?
ONTAP Mediator is a NetApp virtual appliance whose key role is to act as a passive witness to SnapMirror active sync mirrors. It is installed in a third failure domain, distinct from the two ONTAP clusters. In the event of a network partition or unavailability of one mirror, SnapMirror active sync uses Mediator to determine which mirrors are available and adjusts storage path priorities accordingly.
There are three key components in this setup:
1. Primary ONTAP cluster: the host for the primary consistency group in SnapMirror active sync
2. Secondary ONTAP cluster: the host for the mirrored consistency group in SnapMirror active sync
3. ONTAP Mediator
Figure 2) SnapMirror active sync third party quorum
The ONTAP Mediator is an essential component in SnapMirror active sync configurations, serving as a passive quorum witness that supports quorum maintenance and continuous data access during failures without actively initiating switchover operations. By acting as a ping proxy, it enables controllers to verify the status of their peers, especially during network communication issues, by providing an alternative communication path. The Mediator leverages a REST API to manage and relay critical information about cluster configurations, node health, and Consistency Group (CG) relationship statuses. It communicates via node and cluster management LIFs and maintains redundant connections to distinguish between site and Inter-Switch Link (ISL) failures. In the event of a disconnection from the Mediator, an automated failover is triggered to the secondary CG site, ensuring client I/O continuity. The system's resilience is further enhanced by redundant paths like LIF failover, which help maintain the heartbeat mechanism and prevent disruptions in the replication data path.
For more information, review the Documentation for the SnapMirror active sync.
Automatic Unplanned Failover in SnapMirror active sync
In a SnapMirror active sync configuration, an automatic unplanned failover (AUFO) operation occurs in the event of a site failure. When a failover occurs, an automatic unplanned failover to the secondary cluster is executed. The secondary cluster is converted to the primary and begins serving clients. This operation is performed only with assistance from the ONTAP Mediator.
In addition, an AUFO can be triggered if all nodes at a site are failed because of the following reasons:
• Node power down
• Node power loss
• Node panic
You can reestablish the protection relationship and resume operations on the original source cluster using System Manager or the ONTAP CLI.
Configuring SnapMirror active sync
Pre-requisites:
Hardware
SnapMirror active sync exclusively supports 2-node high availability (HA) array clusters consisting of AFF or ASA models. It is crucial to note that both primary and secondary clusters must be the same type, either AFF or ASA. Protection for business continuity utilizing FAS models is not supported.
Refer to the following for more information on SnapMirror active sync supported NetApp models.
• NetApp AFF A-Series
• NetApp AFF C-Series
• NetApp ASA
Note: The purpose of SnapMirror active sync is to safeguard against failures that can render a site inoperable, such as disasters, and ensure uninterrupted business operations. Consequently, SnapMirror active sync is not supported within the same cluster. To establish effective protection, the source and destination clusters must be separate entities and in separate failure domains.
License
You are entitled to use SnapMirror active sync if you have the Data Protection, Premium Bundle, or ONTAP One licenses on both source and destination storage clusters.
Software
To ensure compatibility and optimal performance of your vSphere Metro Storage Cluster (vMSC) with NetApp® SnapMirror® active sync, the following software requirements must be met:
- VMware vSphere: Your environment should be running VMware vSphere version 7.x, and 8.x. These versions are compatible with the SnapMirror active sync solution and allow for full feature utilization.
- ONTAP: Both the source and destination clusters must be running NetApp ONTAP version 9.9.1 or later. If you are implementing a synchronous active-active architecture that requires bi-directional replication and host profiles, as detailed in this article, ONTAP version 9.15.1 or later is mandatory. This ensures that you have the latest features and fixes necessary for a robust and efficient replication setup.
- ONTAP Mediator: An essential component of the SnapMirror active sync configuration, the ONTAP Mediator, must be deployed on a virtual machine (VM) or a physical server that supports the required operating system. The Mediator facilitates automatic failover and recovery operations by serving as an impartial witness to storage system states.
Note: For more details, please refer to NetApp’s documentation for SnapMirror active sync.
Multipathing
SnapMirror active sync leverages Asymmetric Logical Unit Access (ALUA), a standard SCSI and FC mechanism that enables application host multipathing software to communicate with the storage array through paths with priorities and access availability. ALUA designates active optimized paths to the LUN's owning controllers and identifies others as active non-optimized paths. The non-optimized paths are utilized in cases where the primary path fails.
Host access topology
vMSC solutions are classified into two distinct types of topologies, depending on how the vSphere hosts access the storage systems:
1. Uniform host access where the vSphere hosts on both sites are connected to the storage systems across both sites with LUN paths presented to vSphere hosts are stretched across the sites.
2. Non-uniform host access where vSphere hosts at each site are connected only to the local storage system with LUN paths presented limited to the local site.
SnapMirror active sync supports both uniform and non-uniform host access topology.
Network
For SnapMirror active sync to function effectively, it relies on a TCP/IP network to handle the replication transport between storage arrays. To ensure a seamless and efficient replication process, the network must maintain a maximum round trip time (RTT) latency of 10 milliseconds or less between the source and destination storage systems. This low-latency requirement is critical for achieving the desired performance levels for synchronous replication and meeting the stringent recovery point objectives (RPOs) associated with SnapMirror active sync.
ONTAP cluster configuration
Ensure source and destination clusters are configured properly, refer to confirm the ONTAP cluster configuration for more details.
Protection for business continuity
For up-to-date and the necessary steps, refer to NetApp’s documentation to Protect with SnapMirror active sync. Key requirements include a valid SnapMirror Synchronous license and appropriate administrative access. Clusters must be distinct, with all related volumes residing within a single SVM, and peering between primary and secondary SVMs is mandatory. The setup process, which is streamlined in ONTAP versions 9.10.1 and later through System Manager, can also be accomplished using the ONTAP CLI.
Note: Use ONTAP System Manager on the destination cluster. Protection > Relationships, to verify that the protection for business continuity relationship is “Healthy” and “In sync.”
Failure Modes and Impacts
This table outlines vMSC failure modes and their impacts:
| Scenario | NetApp Controller Behavior | VMware HA Behavior |
| Controller single path failure | Controller path failover occurs through ALUA paths established and LUNs and volumes remain connected. | No impact |
| ESXi single storage path failure. | No impact on LUN and volume availability. ESXi storage path fails over to the alternative path. All sessions remain active. | No impact |
| Site 1 Storage failure. | Transparent Application Failover of storage to Site 2. | Site 1 ESXi nodes will incur higher latency due to RTT in accessing storage at Site 2. |
Complete Site 1 failure, including ESXi and controller. |
Transparent Application Failover of storage to Site 2. | Virtual machines on failed Site 1 ESXi nodes fail. HA restarts failed virtual machines on ESXi hosts on Site 2. |
| Complete Site 2 failure, including ESXi and controller. | No Impact to controllers in Site 1 which continues to serve client I/O, unaffected by Site 2 failure. | Virtual machines on failed Site 2 ESXi nodes fail. HA restarts failed virtual machines on ESXi hosts on Site 1. |
| Single ESXi node failure (shutdown). | No impact. Controllers continue to function normally. | Virtual machines on failed ESXi node fail. HA restarts failed virtual machines on surviving ESXi nodes. |
| Multiple ESXi hosts become isolated due to a management network failure. | No impact. Controllers continue to function normally. | If the HA host isolation response is set to Leave Powered On, virtual machines at each site continue to run because the storage heartbeat is still active. A new cluster master will be selected within the network partition. |
| ESXi Management network becomes partitioned between sites. | No impact to controllers. LUNs and volumes remain available. | If the HA host isolation response is set to Leave Powered On, virtual machines at each site continue to run because the storage heartbeat is still active. Partitioned Hosts on the site that does not have a cluster master will elect a new cluster master. |
| Storage & management network ISL failure result in complete datacenter partition. | No Impact to controllers. LUNs and volumes remain available from the primary path. When the storage links are back online, the volumes will automatically perform a delta resync. |
No impact |
| ONTAP System Manager - Management Server failure. | No impact. Controllers continue to function normally. NetApp controllers can be managed using Command Line. |
No impact |
| vCenter Server failure. | No impact. Controllers continue to function normally. | No impact on HA. However, the DRS rules cannot be applied. |
| Mediator Failure. | No impact. Controllers continue to function normally. | No impact |
| Mediator + primary Site Storage failure. | Disruption to storage access for LUNs and volumes with primary path at failed site. Secondary site will be isolated. | ESXi nodes utilizing primary paths at failed site will experience service disruption. |
| Mediator + secondary Site Storage failure. | Primary site will be isolated. LUNs and volumes with primary path will continue to serve I/O. | No impact |
Feedback
