Containers are in Init:ErrImageNeverPull error state
Article ID: 306254
Updated On:
Products
VCF Operations/Automation (formerly VMware Aria Suite)
Issue/Introduction
Symptoms:
Example of pods with such error:
assessment-service-app-##########-24nw8 0/1 Init:ErrImageNeverPull 0 5h30m ##.##.#.### prelude-004.example.com <none> <none>
symphony-logging-daemonset-7phb9 0/1 ErrImageNeverPull 0 5h12m ##.##.#.### prelude-004.example.com <none> <none>
tango-blueprint-service-app-##########-2l8xg 0/1 Init:ErrImageNeverPull 0 5h28m ##.##.#.### prelude-004.example.com <none> <none>
tango-vro-gateway-app-##########-rs7hs 0/1 Init:ErrImageNeverPull 0 5h35m ##.##.#.### prelude-004.example.com <none> <none>
- User is unable to do anything on the environment due to service not being up and running. Pods with Init:ErrImageNeverPull error on one or more nodes can be seen. Execute in order to see the states of the pods
kubectl get pods -n prelude
Example of pods with such error:
assessment-service-app-##########-24nw8 0/1 Init:ErrImageNeverPull 0 5h30m ##.##.#.### prelude-004.example.com <none> <none>
symphony-logging-daemonset-7phb9 0/1 ErrImageNeverPull 0 5h12m ##.##.#.### prelude-004.example.com <none> <none>
tango-blueprint-service-app-##########-2l8xg 0/1 Init:ErrImageNeverPull 0 5h28m ##.##.#.### prelude-004.example.com <none> <none>
tango-vro-gateway-app-##########-rs7hs 0/1 Init:ErrImageNeverPull 0 5h35m ##.##.#.### prelude-004.example.com <none> <none>
Environment
VMware Aria Automation 8.x
Cause
There might be different causes for this issue:
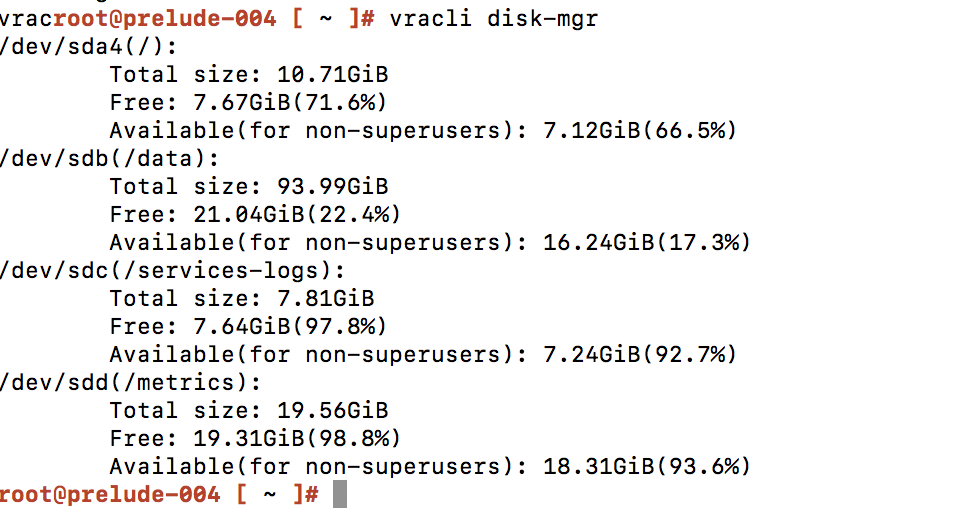
(Disk /data is only 17% free, which is >80% used, which is a problem)
- Ephemeral storage in Prelude is 100% of the disk
- One or more of the storage Prelude disks are completely full or 80%+ full
(Disk /data is only 17% free, which is >80% used, which is a problem)
- Node has been restarted due to unhealthy node status
Resolution
Steps to recover from this state:
- Resize the affected disk and add to it at least 20GB, the more GBs added, the better
- resizing happens through vSphere
- Reboot the affected node and wait some time for things to go into normal state again (about 30-50 mins)
- Aria Automation documentation for increasing disk size indicates to also run the
vracli disk-mgr resizecommand.
- Aria Automation documentation for increasing disk size indicates to also run the
Alternative to the reboot is to execute the “/opt/scripts/restore_docker_images.sh” script on the affected node(s).
Feedback
Yes
No
Powered by
